Catalog Organisation
When a user PUTs files to the NLDS, the files are recorded in a catalog on behalf of the user. The user can then list which files they have in the catalog and also search for files based on a regular expression. Additionally, users can associate a label and tags, in the form of key:value pairs with a file or collection of files.
Figure 1 shows a simplified version of the structure of the catalog, with just the information relevant to the user remaining.
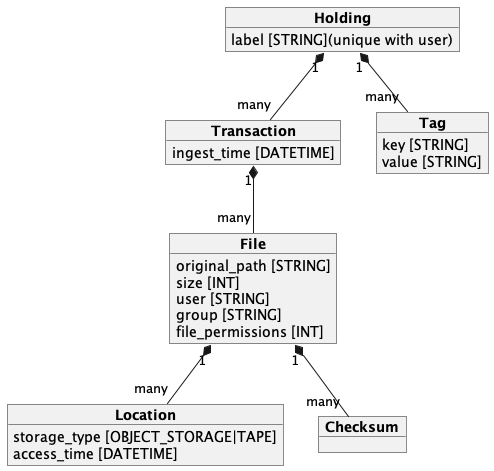
Figure 1: Simplified view of the NLDS data-catalog
The terms in figure 1 are explained below:
Holdings
Holdings are collections of files, that the user has chosen to collect together and assign a label to the collection. A reason to collect files in a holding might be that they are from the same experiment, or climate model run, or measuring campaign. Users can give the holding a label, but if they do not then a seemingly random label will be assigned to the holding. This is actually the id of the first transaction that created the holding. Users can change the label that a holding has at any time.
Holdings are created when a user PUTs a file into the NLDS, using either the
nlds put or nlds putlist command. These commands take a label
argument with the -l or --label option. The first time a user PUTs a
file, or list of files, into a holding, the holding will be created.
If a label is specified then the holding will be assigned that label.
If a label is not specified then the seemingly random label will be
assigned.
After this, if a user PUTs a file into the NLDS and specifies a label for a holding that already exists, then the file will be added to that holding. If the holding with the specified label does not exist then the file will be added to a new holding. This leads to the behaviour that, if a label is not specified when PUTting a file (or list of files) into the NLDS, a new holding will be created for each file (or list of files).
Reading this, you may ask the question “What happens if I add a file that already exists in the NLDS?”. This is a good question, and a number of rules cover it:
1. The original_path of a file must be unique within a holding. An
error is given if a user PUTs a file into a holding that already exists and
the file with original_path already exists in the holding.
2. The original_path does not have to be unique across holdings.
Multiple files with the same original_path can exist in the NLDS, providing
that they belong to different holdings, with different labels.
3. Users can GET files without specifying which holding to get them from,
i.e. the -l or --label option is not given when nlds get or nlds
getlist commands are invoked. In this case, the newest file is returned.
Organising the catalog in this way means that users can use the NLDS as an iterative backup solution, by PUTting files into differently labelled holdings at different times. GETting the files will returned the latest files, while leaving the older files still accessible by specifying the holding label.
Transactions
Transactions record the user’s action when PUTting a file into the NLDS. As alluded to above, in the Holdings section, each holding can contain numerous transactions. A transaction is created every time a user PUTs a single file, or list of files, into the NLDS. This transaction is assigned to a holding based on the label supplied by the user. If a label is specified for a number of PUT actions, then the holding with that label will contain all the transactions arising from the PUT actions.
A transaction contains very little information itself, but its place in the
catalog hierarchy is important. As can be seen in figure 2, it contains a list
of files and it belongs to a holding. This is the mapping that allows
users to add files to holdings iteratively and at different times. For
example, a user may PUT the files file_1, file_2 and file_3 into the
holding with backup_1 label on the 23rd Dec 2023. The user may then
PUT file_4, file_5 and file_6 into the same holding on the 4th
Jan 2024, by specifying the label backup_1. This will have the effect of
creating two transactions - one containing file_1, file_2 and file_3
and the other containing file_4, file_5 and file_6, with the
backup_1 holding containing both transactions. Therefore, all files
(file_1 through to file_6) are associated with the backup_1
holding at particular ingest_times.
If, at a later time, the user puts file_1 to file_6 into
another holding with a label of backup_2 then another
transaction will be created with a later ingest_time and the files
will be associated with the transaction and the backup_2 holding.
The files may have changed in the interim and, therefore, the files
with the same filenames may be different in backup_2 than they are in
backup_1. This is the mechanism by which NLDS allows users to perform
iterative backups and how users can get the latest files, via the ingest_time.
File
The very purpose of NLDS is the long term storage of files, recording their
details in a data catalog and then accessing (GETting) them when they are
required. The file object in the data catalog records the details of a
single file, including the original path of the file, its size and the
ownership and permissions of the file. Users can GET files in a number of ways,
including by using just the original_path where the NLDS will return the
most recent file with that path.
Also associated with files is the checksum of the file. NLDS supports different methods of calculating checksums, and so more than one checksum can be associated with a single file.
Location
The user interacts with the NLDS by PUTting and GETting files, without knowing (or caring) where those files are stored. From a user view, the files are stored in the NLDS. In reality the NLDS first writes the files to object storage. Later the files are backed up to tape storage. When the NLDS cache approaches capacity, files will be removed from the cache depending on a policy which takes into account several variables, including when they were last accessed. If a user subsequently GETs a file that has removed from the cache then the NLDS will first retrieve the file from the tape storage to the cache before copying it to the user specified target.
The location object in the Catalog database is associated to a file, and can have one of three states:
1. The file is held on the cache only. It will be backed up to the tape storage later.
2. The file is held on both the cache and tape storage. Users can access the file without any staging required by the NLDS.
3. The file is held on the tape storage only. If a user accesses the file then the NLDS will stage it to the tape storage, before completing the GET on behalf of the user. The user does not need to concern themselves with the details of this. However, accessing a file that is stored only on tape will take longer than if it was held on cache.