The CFA-Xarray Engine
cfapyx is registered as an available backend to xarray when installed into your virtual environment, which means that xarray will
collect the package and add it to a list of backends on performing import xarray.
1. Entrypoint
The CFANetCDFBackendEntrypoint() class provides a method called open_dataset which feeds the output of open_cfa_dataset directly back into xarray.
There are other methods which may be useful to implement in the future, but for now only the basic opener is used.
Note
Most CFA classes in this module inherit from equivalent NetCDF4 classes directly from Xarray, since only a small number of additional or override methods are required. There is therefore a large number of methods with CFA classes that are not used directly within this package.
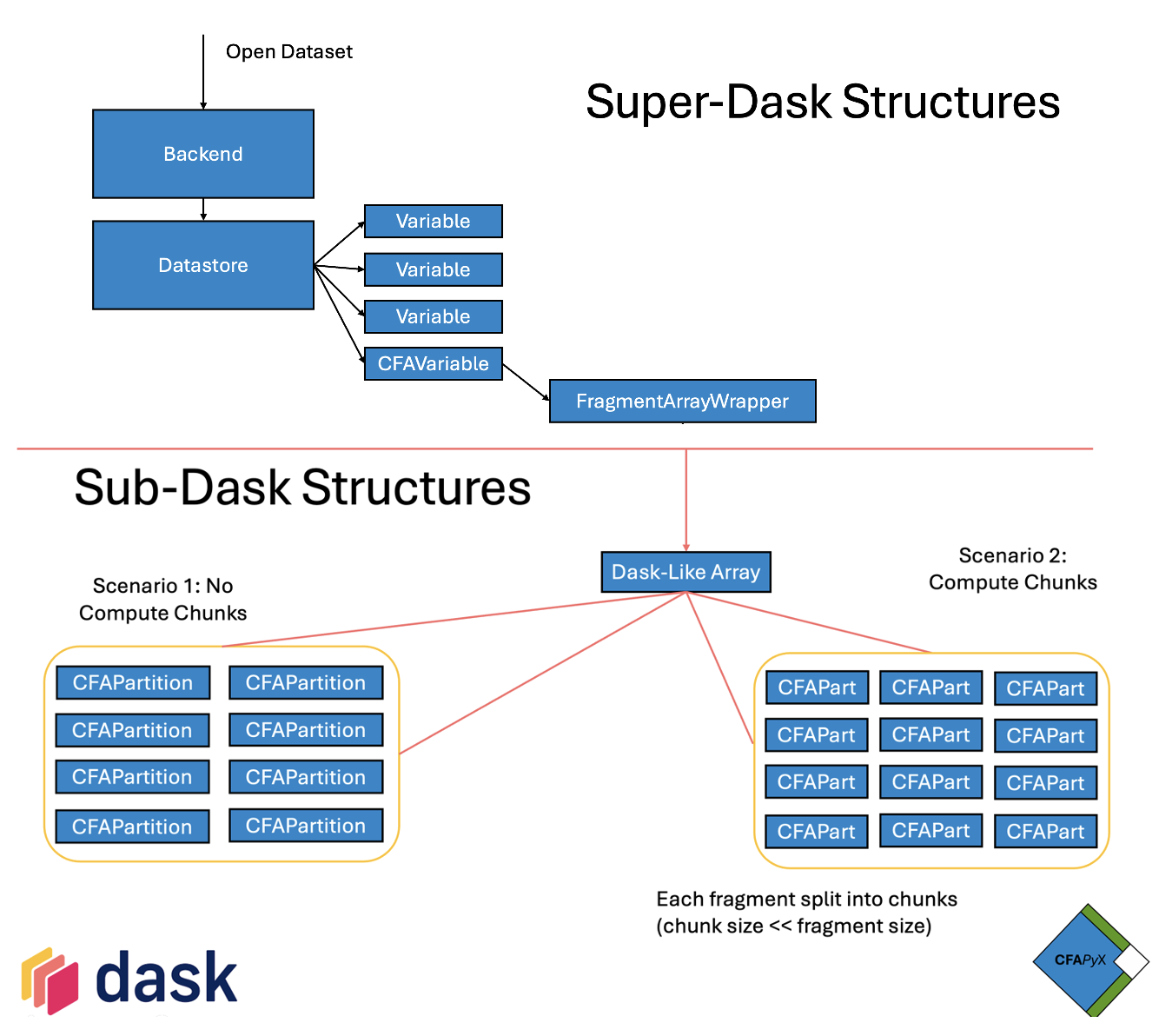
Opening a CFA dataset requires opening the CFA-netCDF file into a CFADataStore object (inherits from Xarray’s NetCDF4DataStore) which is then used as the store attribute in later methods inherited from parent Xarray/NetCDF classes.
2. Datastore
The CFA Datastore handles global and group variables where a group is present, and determines which variables are aggregated variables, which are decoded in open_cfa_variable
The set of variables are returned from get_variables as an xarray FrozenDict object of xarray Variable objects. Each Variable is defined using the dimensions, attributes
and encoding from the CFA file, but the data is more complicated.
3. Data from Fragments
Xarray comes with an included LazilyIndexedArray wrapper for containing indexable Array-like objects. The data is indexed via this first level of wrapper so the data isn’t loaded immediately upon creating the Xarray variable.
cfapyx provides an Array-like wrapper class called FragmentArrayWrapper for handling calls to the whole array of all fragments. At this point we are still dealing with what looks like a single Array in xarray, rather than a
set of distributed Fragments. cfapyx handles these fragments as individual CFAPartition objects when no chunks are present, and ChunkWrapper objects otherwise.
These are provided to the higher level Xarray wrapper by way of a Dask array, which is created as the data attribute of each variable.
This means most of the complicated maths to relate an array partition to specific fragments is actually handled by Dask, the only thing the CFAPartition objects have to do is act like indexable Arrays that only load the data when they are indexed.
Since there are several Array-like objects in cfapyx, these all inherit from classes in cfapyx.partition, in the order ArrayLike -> SuperLazyArrayLike -> ArrayPartition. The CFAPartition class is an example of an ArrayPartition while the
FragmentArrayWrapper and ChunkWrapper classes are merely SuperLazyArrayLike children.
Loading each array partition is done using the python netCDF4 library to load the associated fragment file for this partition, selecting the specific variable (from `location`) and loading a section of the array as a numpy array - depending on the
partition structure. Performing the slice operations on the netCDF4 dataset at the latest point ensures the minimal amount of memory chunks are loaded from the file, since any slicing operations are optimised by Dask before being applied to the source data.
4. Result
All of the above is abstracted from the user into the simple open_dataset command from Xarray. The dataset which is built looks like any other xarray dataset, which includes the loaded attributes and a Dask array for each variable.
This only becomes an array of ‘real’ data following a compute() or plot() method (or equivalent), otherwise the data has yet to be loaded. Performing slices or reduction methods is handled entirely by Dask such that the operations are
combined and applied at the latest stage for optimal performance.
If you would like to read more about lazy loading in general, see this SaturnCloud Blog or visit the Dask Documentation.
For more detail specifically on CFA, see either the CFA specifications or our page on the Inspiration for CFA. The CFA specifications version 0.6.2 will be added to CF-conventions 1.12 in November 2024 with some minor changes.
- Finally if you would like to find out about alternative ways of handling distributed data, specifically for cloud applications, see one of the following:
padocc (CEDA): Pipeline to Aggregate Data for Optimal Cloud Capabilities
Kerchunk: Reference format
Zarr: Cloud Optimised format